
L’une des tâches que la fouille nous permet d’effectuer est la catégorisation automatique. Par exemple il nous est possible en utilisant ce type de processus de prédire de quel parti politique provient un document. Ce qui est particulièrement intéressant dans ce type d’analyse, ce sont les erreurs, c’est-à-dire les documents dont le système a incorrectement prédit l’appartenance. Ces erreurs sont aussi parlantes, voire plus, que les documents pour lesquels le parti a été correctement prédit. En effectuant la catégorisation automatique des documents produits par les partis politiques, on peut obtenir un portrait révélateur de certaines tendances lexicales des partis ainsi que de leur proximité.
La catégorisation automatique se fait en deux temps : l’apprentissage et le test. Lors de la phase d’apprentissage, on donne à la machine une partie du corpus, associée aux catégories qu’elle doit apprendre. Par exemple, dans ce cas-ci, l’outil de fouille connaît le nom du parti qui a publié le communiqué et il doit s’entraîner à reconnaître ce qui distingue un parti d’un autre. Ensuite, nous fournissons à la machine le corpus de test. Cette fois, le nom du parti n’est pas lié aux communiqués. Sur la base de ce qu’il a appris dans la phase de test, l’outil doit associer un document à un parti.
Si vous voulez en savoir plus sur la méthodologie, cliquez ici.
Pour voir tout de suite l’analyse des résultats, cliquez ici.
Résultats
Apprentissage
Le corpus d’apprentissage est formé des communiqués, billets de blogue et extraits de plateforme publiés sur les sites officiels des partis du 2 août au 29 septembre, pour un total de 533 documents. Sur le lot, 515 ont été correctement catégorisés. La justesse de la machine est donc de 97%. Soulignons ici que la justesse aléatoire se situe à 20%. En effet, l’outil a une chance sur cinq d’avoir la bonne réponse, étant donné qu’il y a cinq catégories (ou partis).
Les résultats complets peuvent être observés à la figure 1. Afin de bien la lire, il faut comprendre les mesures de précision et de rappel.
- La mesure de précision calcule le nombre de documents qui ont été correctement placés dans la catégorie A par rapport à l’ensemble des documents prédits dans la catégorie A. Si la mesure de précision est très basse, il y aura beaucoup de bruit dans nos résultats. Ainsi, beaucoup de documents appartenant aux autres catégories, comme B ou C, qui seraient injustement placés dans la catégorie A.
- La mesure de rappel calcule le nombre de documents qui ont été prédits dans la catégorie A par rapport à l’ensemble des documents qui font partie de la catégorie A. Si la mesure de rappel est très basse, il y aura beaucoup de silence dans nos résultats. Ainsi, beaucoup de documents qui appartiennent à la catégorie A ne seraient pas placés dans la catégorie A.
Afin de rendre ces explications plus concrètes, observons les résultats du Bloc québécois à la figure 1.
- La précision est représentée dans la première colonne du tableau. On peut voir que 47 documents ont été attribués au Bloc québécois et que les 47 ont tous été réellement publiés par les bloquistes. La précision est donc de 100%.
- Le rappel est représenté dans la première ligne du tableau. Au total, 49 documents proviennent du Bloc québécois. 47 ont été attribués au Bloc québécois, 1 au NPD et 1 au Parti libéral. Le rappel est donc de 47 sur 49, soit 95,92%.
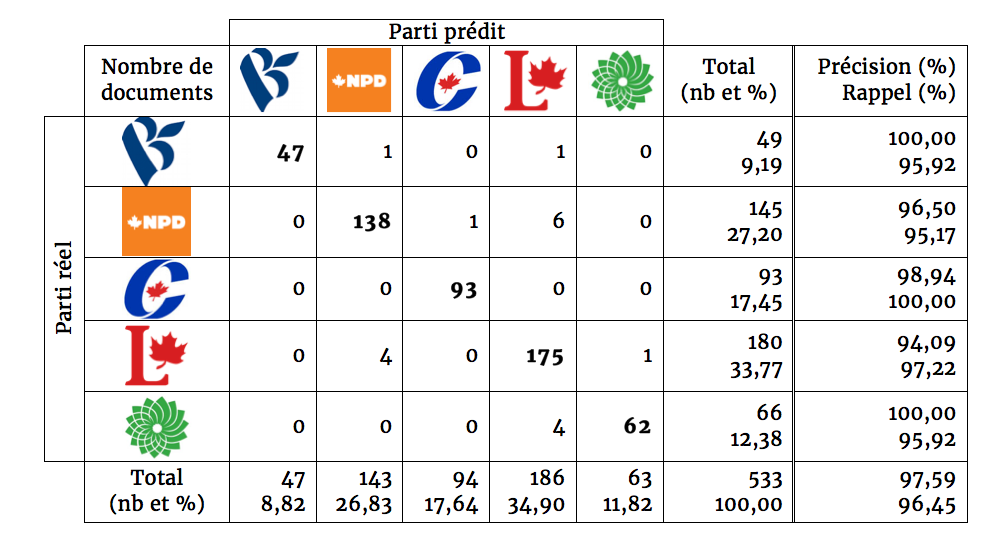
Figure 1. Résultats obtenus avec le corpus d’apprentissage (2 août au 29 septembre)
Soulignons le nombre peu élevé de documents publiés par le Bloc québécois, qui n’atteint même pas 10% du corpus d’apprentissage. Le Parti vert n’est pas très loin non plus, avec 12%. À l’autre extrême, le Parti libéral dépasse largement ses adversaires pour le nombre de publications (34%). Le Nouveau Parti démocratique le suit avec 27% des publications. Finalement, le Parti conservateur (17%) se tient près de la moyenne statistique (20%). Alors que les résultats sont bons avec le corpus d’apprentissage, c’est-à-dire que la machine est capable de reconnaître les mots nécessaires à l’identification du parti dans 97 % des cas, reste à voir si les mots retenus seront suffisants pour faire la prédiction pour de nouveaux documents.
Test
Le corpus test est formé des mêmes types de documents que le corpus d’apprentissage. La période de publication des documents est toutefois différente, soit du 30 septembre au 8 octobre. Il est composé de 140 documents. Il est étonnant de voir que le NPD dépasse maintenant le Parti libéral pour le pourcentage de publications; ils ont respectivement 37% et 25%. Autre changement : le Parti vert (19%) dépasse le Parti conservateur (12%). De son côté, le Bloc québécois occupe une place encore plus restreinte, avec 6% des publications.
Sur les 140 documents, 115 ont été correctement catégorisés, pour une justesse de 82,1 %. La précision est égale à 81,7 % et le rappel atteint 77,1%. Concernant les résultats beaucoup plus faibles du Bloc québécois, rappelons que son corpus d’apprentissage est le plus mince des cinq partis. De plus, on remarque que le plus grand nombre de confusions provient d’un mélange entre NPD et Parti libéral, autant dans le corpus d’apprentissage que dans le corpus test. Il peut s’agir d’une conséquence de la proximité thématique entre les deux partis, comme nous l’avons vu dans un précédent billet. Pour l’ensemble des résultats, consultez la figure 2.

Figure 2. Résultats obtenus avec le corpus test (30 septembre au 8 octobre)
Analyse
Comme nous pouvons le constater dans la figure 2, vingt-cinq documents n’ont pas été correctement prédits. La prochaine étape est d’observer ces erreurs afin de tenter de les comprendre. En effet, elles peuvent être révélatrices d’un changement ou d’une anomalie dans le discours d’un parti. Nous avons répertorié quatre cas de figure.
Québec ou Canada?
Un communiqué de presse du Parti libéral paru le 7 octobre a été attribué au Bloc québécois à cause des mots “Québec” et “Montréal”, utilisés à plusieurs reprises. Il est rare que les partis, outre le Bloc québécois, s’adressent aussi directement à une province.
Inversement, un document du Bloc québécois du 28 septembre a été attribué au Parti libéral. Traitant de paradis fiscaux, le communiqué ne contient pas une seule fois le mot “Québec”. Cet exemple nous permet de démontrer une particularité de l’algorithme retenu pour procéder à la catégorisation. Il est sensible non seulement à la présence, mais également à l’absence de termes dans un document pour pouvoir prédire sa catégorie.
Singer l’adversaire
Attaquer ses adversaires est monnaie courante lors de campagnes électorales. Dans plusieurs documents faisant partie des erreurs de prédiction, on trouve ce type de document. Le 3 octobre 2015, par exemple, le Parti vert explique dans son blogue son opposition au projet de Loi sur la tolérance zéro face aux pratiques culturelles barbares. Il emploie des mots et des idées typiquement mis de l’avant par le Parti conservateur, notamment dans le domaine juridique, expliquant pourquoi le document a été prédit pour celui-ci. Le Parti vert cherche ainsi à mettre en lumière l’incohérence du gouvernement Harper qui s’oppose à une commission sur les femmes autochtones assassinées et disparues.
S’inspirer de l’adversaire
Le 1er octobre, le Parti conservateur a publié une lettre ouverte de Stephen Harper adressée à la fonction publique. Or, la machine a plutôt prédit que ce document provenait du Parti libéral. En effet, ce dernier a fréquemment utilisé cette formule pour transmettre son message. De plus, il y est beaucoup question de familles et de santé, thèmes plus souvent abordés par les libéraux que par les conservateurs dans les communiqués de presse.
Le Partenariat transpacifique brouille les cartes
Huit documents traitant du Partenariat transpacifique ont été mal classés par la machine.
- 5 publiés par le Nouveau Parti démocratique
- 2 prédits Parti libéral
- 2 prédits Parti vert
- 1 prédit Bloc québécois
- 3 publiés par le Bloc québécois
- 2 prédits Nouveau Parti démocratique
- 1 prédit Parti libéral
D’une part, on peut attribuer ces erreurs à l’absence du thème dans le corpus d’apprentissage, qui regroupe les documents ayant été publiés entre le 2 août et le 29 septembre 2015. Cependant, une étude des documents nous permet de voir que le Partenariat transpacifique implique plusieurs sphères d’activités de l’économie canadienne et que les documents de campagne qui s’y rapportent traitent de multiples enjeux comme l’agriculture, l’accès aux médicaments génériques, les relations internationales et la liberté sur internet. De plus, certains communiqués se concentrent sur un seul aspect du partenariat alors que d’autres en regroupent plusieurs. Ainsi, l’hétérogénéité du thème rend sa prédiction plus complexe.
Conclusion
Comme on a pu le voir, la catégorisation automatique des communiqués de presse, billets de blogue et extraits de plateforme publiés par les partis politiques en cours de campagne permet de faire ressortir des cas particuliers où les partis sortent de leur discours habituel, se rapprochant parfois de leurs adversaires. D’ici quelques jours, la période électorale sera terminée et nous disposerons alors d’un corpus complet. Bien que plusieurs sujets soient spécifiques à l’actualité, certains sont récurrents d’une campagne à l’autre. Il sera donc intéressant, dans quelques années (ou quelques mois, selon les résultats du 19 octobre), d’utiliser le corpus 2015 pour faire l’apprentissage de la machine et ainsi prédire l’appartenance des documents parus. Par ailleurs, la présente analyse exclut les plateformes électorales, qui n’étaient pas toutes disponibles au moment de créer le corpus d’apprentissage. Comme elles couvrent normalement tous les enjeux jugés pertinents par un parti pour la campagne en cours, il serait intéressant de refaire l’exercice en incluant les plateformes électorales dans le corpus d’apprentissage.
Méthodologie
La catégorisation est une tâche prédictive qui repose sur un apprentissage assisté de la machine. À partir d’un corpus d’apprentissage, dans notre cas composé de 533 documents diffusés par les partis politiques du 2 août au 29 septembre, la machine s’entraine à reconnaître les caractéristiques des différentes catégories pour qu’elle soit à même de prédire le parti auquel le document est associé. Ainsi, lors de cette étape, les noms des partis sont fournis à la machine afin qu’elle détermine les mots capables de prédire les réponses à un nouveau jeu de données. Cette opération pose deux grands défis. Premièrement, l’algorithme doit être capable de se souvenir de ce qu’il a appris et il doit être capable de généraliser les apprentissages à des contenus nouveaux. En catégorisation, la taille du corpus d’apprentissage est un facteur important dans le succès de l’opération. Plus le nombre de catégories à prédire est grand, plus le corpus d’apprentissage devra être volumineux. Inversement, s’il y a peu de catégories à prédire, l’apprentissage peut se faire à partir d’une poignée de documents. Les documents du corpus doivent être représentatifs de chacune des catégories à prédire. L’algorithme doit avoir des exemples de chacune des catégories pour apprendre de leurs caractéristiques pour être en mesure d’identifier les caractéristiques dans un nouveau document.
Après plusieurs itérations sur le corpus d’apprentissage, nous avons déterminé les paramètres optimaux pour effectuer la catégorisation. L’algorithme choisi est le Naive Bayes, qui classe les documents en catégories en fonction de la probabilité d’appartenance d’un document dans chacune des catégories. La mesure d’appartenance est calculée en fonction de la présence ou de l’absence de termes à l’intérieur du document évalué. Nous avons conservé les 760 termes les plus discriminants selon une mesure de chi-carré maximum, calculée en fonction du nombre d’occurrences d’un terme. Nous avons randomisé les données, car l’algorithme d’apprentissage est sensible à l’ordre d’apparition des documents. La méthode de validation croisée utilisée est le leave one out.